






随着大数据时代的到来,实时数据处理与分析的需求日益凸显,作为开源流处理框架的佼佼者,Apache Flink凭借其高吞吐、低延迟的特性,在大数据处理领域获得了广泛关注,本文将详细介绍Flink实时数仓分层在12月的最新发展,包括产品特性、使用体验、与竞品对比、优点与缺点以及目标用户群体分析。
产品特性
1、流式数据处理:Flink提供了实时数据流处理的强大能力,支持多种数据源和接收器,能够处理大规模数据流并保证高并发下的稳定性。
2、精确一次语义:Flink保证了数据处理的精确一次语义,避免了数据重复或丢失的问题。
3、强大的状态管理:Flink提供了状态管理功能,支持复杂的事件驱动处理和会话计算。
4、容错性设计:Flink具有高度的容错性,能够自动检测和恢复系统故障,确保数据处理的连续性。
5、数仓分层架构:在数仓分层方面,Flink提供了清晰的架构层次,从原始数据到特征工程,再到业务逻辑层,每一层都有明确的职责和优化策略。
使用体验
在使用Flink构建实时数仓的过程中,用户能够感受到其强大的性能和稳定的处理能力,数仓分层的设计使得数据处理流程更加清晰,开发者可以更加专注于业务逻辑的实现,Flink的API设计简洁明了,学习曲线相对平缓,易于上手,其社区资源丰富,遇到问题可以迅速得到解答。
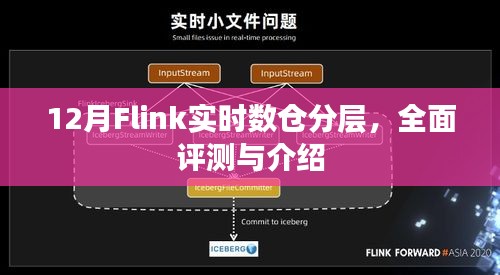
与竞品对比
1、Apache Kafka:Kafka作为大数据领域的消息中间件,主要侧重于数据的传输和队列,而Flink在实时数据处理方面更具优势,提供了完整的流处理框架和丰富的数据处理算子。
2、Spark Streaming:Spark Streaming是Spark生态系统中的流处理组件,与Flink相比,Flink在处理实时数据流时具有更低的延迟和更好的可扩展性。
3、其他流处理框架:与其他流处理框架相比,Flink在性能、稳定性和易用性方面均表现出色,特别是在数仓分层方面有着独特的优势。
优点与缺点
优点:
1、低延迟:Flink的流处理机制保证了数据处理的实时性,适用于对时间敏感的应用场景。
2、高性能:Flink具有高性能的处理能力,能够应对大规模数据流的挑战。
3、丰富的生态:Flink拥有完善的生态系统,可以与多种大数据组件无缝集成。
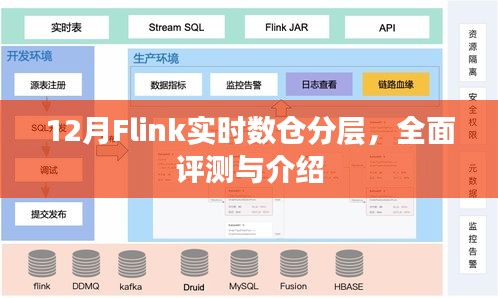
4、数仓分层设计:Flink在数仓分层方面有着独特的优势,使得数据处理流程更加清晰和高效。
缺点:
1、学习曲线:对于初学者来说,Flink的API和概念可能需要一定的时间去熟悉和掌握。
2、资源需求:在处理大规模数据流时,Flink需要较多的计算资源,对硬件有一定的要求。
目标用户群体分析
Flink的实时数仓分层解决方案主要适用于需要进行实时数据处理和分析的企业和团队,特别是对数据实时性要求较高的场景,如金融风控、物联网、实时推荐系统等,Flink都能提供高效的解决方案,对于已经有一定大数据基础,并且希望构建完善数仓体系的团队,Flink也是一个不错的选择。
Flink凭借其低延迟、高性能和数仓分层设计的优势,在实时数据处理领域占据了重要地位,本文详细介绍了Flink的产品特性、使用体验、与竞品对比、优点与缺点以及目标用户群体分析,希望能为读者提供更加全面的了解。
转载请注明来自戴码定制,本文标题:《12月Flink实时数仓分层详解与全面评测》





 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...