






12月14日
随着大数据技术的不断发展,实时数据处理的需求日益凸显,在这样的背景下,SparkFlink作为一种强大的实时数据处理框架,受到了广泛关注,本文将详细介绍SparkFlink实时数仓架构,并重点讨论要点一、要点二和要点三,本文风格偏向正式,确保读者能够全面了解并深度理解这一技术架构。
在当今大数据时代,企业对于数据的实时处理和分析需求愈发强烈,SparkFlink作为一种兼具批处理和流处理能力的框架,为企业提供了强大的实时数据处理解决方案,本文将带您走进SparkFlink实时数仓架构的世界,一起探讨其核心技术要点。
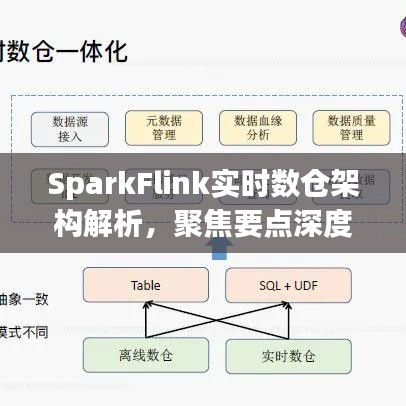
SparkFlink实时数仓架构概述
SparkFlink实时数仓架构主要包括以下几个部分:数据源、数据预处理、实时计算、数据存储和数据分析与可视化,数据源可以是各种实时产生的数据,如日志、消息队列等;数据预处理负责对数据进行清洗、转换等操作;实时计算是SparkFlink的核心部分,负责数据的实时处理和分析;数据存储则将处理后的数据持久化存储;数据分析与可视化则为用户提供直观的数据分析结果。
要点一:实时计算
实时计算是SparkFlink架构中的核心部分,其主要包括流数据处理和批流一体处理,流数据处理能够实现对数据的实时接收、处理和输出,确保数据的实时性,而批流一体处理则结合了批处理和流处理的优势,能够在处理大量历史数据的同时,保证对新数据的实时处理能力,SparkFlink的容错机制和状态管理功能也为其提供了强大的支撑。
要点二:数据预处理与存储
在SparkFlink实时数仓架构中,数据预处理和存储同样重要,数据预处理负责对原始数据进行清洗、转换和整合等操作,以确保数据的质量和一致性,而数据存储则负责将处理后的数据持久化存储,为后续的数据分析和使用提供基础,在这一部分,我们需要关注数据的质量管理、存储方案的选择以及数据存储的可靠性等问题。

要点三:数据分析与可视化
数据分析与可视化是SparkFlink实时数仓架构的最终环节,也是企业用户最为关注的部分,在这一环节,我们需要利用SparkFlink提供的数据处理结果,结合数据分析工具和方法,进行深度的数据分析和挖掘,通过可视化工具将分析结果直观地呈现出来,帮助企业用户更好地理解和利用数据,在这一部分,我们需要关注数据分析的方法论、可视化工具的选择以及数据分析与业务需求的结合等问题。
本文详细介绍了SparkFlink实时数仓架构的核心理念和关键技术,重点讨论了要点一、要点二和要点三,通过本文的阐述,相信读者对SparkFlink实时数仓架构有了全面的了解,在实际应用中,我们需要根据企业的实际需求和技术环境,灵活应用SparkFlink的技术要点,构建高效的实时数仓解决方案。
随着大数据技术的不断发展,SparkFlink实时数仓架构将在未来发挥更加重要的作用,我们期待更多的企业和开发者能够关注和掌握这一技术,为大数据领域的发展做出更大的贡献。

转载请注明来自戴码定制,本文标题:《SparkFlink实时数仓架构深度解析,聚焦要点探讨与解析》





 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...